

* 이 글은 제가 공부하기 위해 최대한 사실에 입각해 내용을 적으려고 하지만 일부 내용들이 정확하지 않을 수 있습니다.
혹시나 잘못된 부분이 있으면 너그럽게 이해해 주시고 피드백 부탁드려요!
1. 데이터 베이스 응용 프로젝트 개발
테이블 생성
• 개요
– 테이블 생성은 테이블에 대한 구조를 정의하고, 데이터를 저장하기 위한 공간을 할당하는 과정
– 테이블에 대한 구조 정의는 테이블을 구성하는 칼럼의 데이터 타입과 무결성 제약조건을 정의하는 과정
• 테이블 이름 정의 방법
– 문자(A-Z, a-z)로 시작, 30자 이내
– 문자(a-z, A-Z), 숫자(0-9), 특수문자(_,$,#) 사용 가능
– 대소문자 구별 없음, 소문자로 저장하려면 단일 인용부호 이용
– 동일 사용자가 소유한 다른 객체의 이름과 중복 불가
– 서로 다른 테이블에서 동일한 데이터를 저장하는 칼럼 이름은 가능하면 같은 이름을 사용
– 필요에 따라 언제든지 테이블 생성 가능
– 완성된 설계도에 따라 테이블을 생성 권장
테이블 생성 방법
• 사용법

– GLOBAL TEMPORARY : 임시 테이블을 만들기 위한 키워드로서 테이블 구조는 모든 세션에서 볼 수
있지만, 데이터는 테이블을 생성한 세션에서만 조회 가능
– schema : 데이터베이스 사용자 계정과 같은 의미
– table : 생성하고자 하는 테이블 이름
– column : 테이블에 포함되는 칼럼 이름
– datatype : 칼럼에 대한 데이터 타입과 길이
– DEFAULT expression : 데이터 입력 시 값이 생략된 경우에 입력되는 기본 값
– column_constraint_clause : 칼럼에 대해 정의되는 무결성 제약조건
• 사용 예
– 연락처 정보를 저장하기 위한 주소록(address) 테이블을 생성하여라.


DEFAULT 옵션
• 기능
– 칼럼의 입력 값이 생략될 경우에 NULL 대신에 입력되는 기본 값을 지정하기 위한 기능
– 기본값 : 리터럴 값, 표현식, SQL함수, SYSDATE, USER를 사용
– 칼럼이나 의사칼럼(NEXTVAL, CURRVAL)은 사용할 수 없음
• 칼럼 정의 시 기본 값 설정 예

테이블 생성 확인
• DESC [RIBE] 명령어
– 테이블의 생성 여부와 테이블의 구조를 확인하기 위한 명령어
– 칼럼 이름, 데이터 타입과 크기, NOT NULL 무결성 제약조건
• 사용법

서브쿼리를 이용한 테이블 생성
• 개요
– CREATE TABLE 명령문에서 서브쿼리 절을 이용하여 다른 테이블의 구조와 데이터를 복사하여
새로운 테이블 생성 가능
– 서브쿼리의 출력 결과가 테이블의 초기 데이터로 삽입
• 기능
– CREATE TABLE 명령문에서 지정한 칼럼 수와 데이터 타입과 반드시 일치
– 칼럼 이름을 명시하지 않을 경우 서브쿼리 칼럼 이름과 동일
– 무결성 제약조건은 NOT NULL 조건만 복사
• 기본 키, 참조 키와 같은 무결성 제약조건은 사용자의 재정의 필요
– 디폴트 옵션에서 정의한 값은 그대로 복사
• 사용법

• 예제 데이터 입력
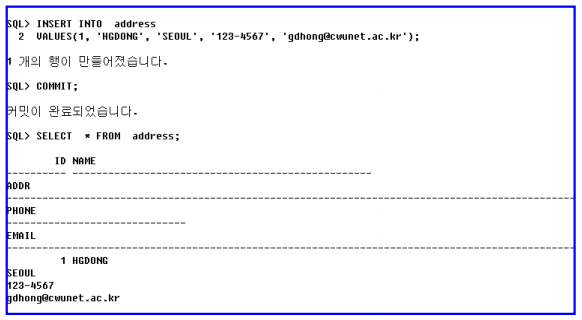
• 사용 예
– 서브쿼리 절을 이용하여 주소록 테이블의 구조와 데이터를 복사하여 addr_second 테이블을 생성하여라.

테이블 구조 복사
• 기존 테이블의 구조만 복사
– 서브쿼리를 이용한 테이블 생성 시 데이터는 복사하지 않고 기존테이블의 구조만 복사 가능
– 서브퀴리의 WHERE 조건절에 거짓이 되는 조건을 지정하여 출력 결과 집합이 생성되지 않도록 지정
• 사용법

– condition : 출력 결과가 항상 거짓인 조건을 명시.
예) WHERE 1=2
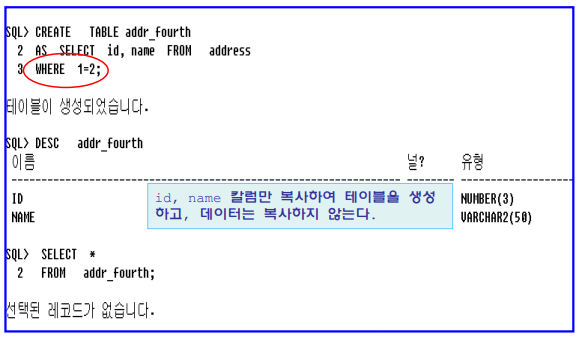
• 사용 예
– 주소록 테이블에서 id, name 칼럼만 복사하여 addr_fourth 테이블을 생성하여라.
단, 데이터는 복사하지 않는다.
2. 테이블 구조 변경
서브쿼리를 이용한 테이블 생성
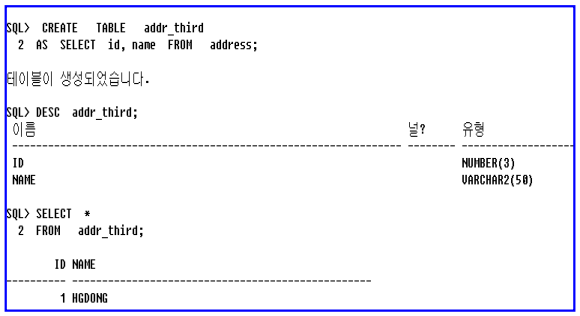
• 사용 예
– 주소록 테이블에서 id, name 칼럼만 복사하여 addr_third 테이블을 생성하여라.
테이블 구조 변경
• 개요
– ALTER TABLE 명령문 이용
– 칼럼 추가, 삭제, 타입이나 길이의 재정의와 같은 작업
• 칼럼추가
– ALTER TABLE … ADD 명령문 사용
– 추가된 칼럼은 테이블의 마지막 부분에 생성, 위치 지정 불가능
– 추가된 칼럼에도 기본 값을 지정 가능
– 수정한 테이블에 기존 데이터가 존재하면 칼럼 값은 NULL로 입력
• 사용법

테이블에 칼럼 추가
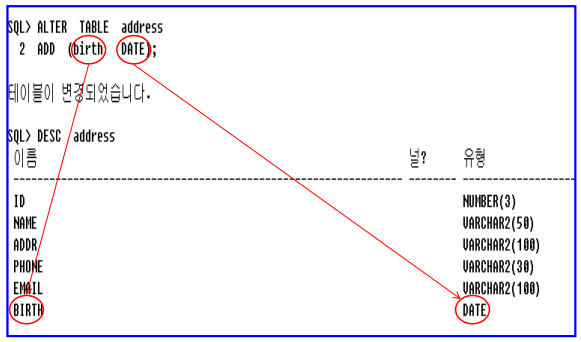
• 사용 예
– 주소록 테이블에 날짜 타입을 가지는 birth 칼럼을 추가하여라.
• 실습 예
– 주소록 테이블에 문자 타입을 가지는 comment 칼럼을 추가하여라.
기본 값은 "No Comment"로 지정하여라.

테이블 칼럼 삭제
• 기능
– 테이블 내의 특정 칼럼과 칼럼의 데이터를 삭제
– ALTER TABLE … DROP COLUMN 명령문 사용
– 2개 이상의 칼럼이 존재하는 테이블에서만 삭제 가능
– 하나의 칼럼 삭제 명령문은 하나의 칼럼만 삭제 가능
• 사용법

• 사용 예
– 주소록 테이블에서 comment 칼럼을 삭제하여라.
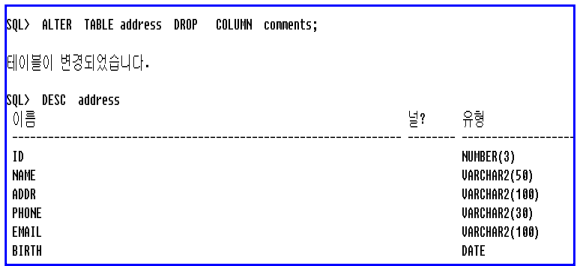
테이블 칼럼 변경
• 기능
– 테이블에서 칼럼의 타입, 크기, 기본 값 변경 가능
– ALTER TABLE … MODIFY 명령문 이용
– 기존 칼럼에 데이터가 없는 경우
• 칼럼 타입이나 크기 변경이 자유로움
– 기존 데이터가 존재하는 경우
• 타입 변경은 CHAR와 VARCHAR2만 허용
• 변경한 칼럼의 크기가 저장된 데이터의 크기보다 같거나 클 경우 변경 가능
• 숫자 타입에서는 정밀도 증가 가능
– 기본 값의 변경은 변경 후에 입력되는 데이터부터 적용
• 사용법

• 사용 예
– 주소록 테이블에서 phone 칼럼의 데이터 타입의 크기를 50으로 증가하여라.

테이블 이름 변경
• 기능
– RENAME 명령문 사용
• 객체의 이름을 변경하는 DDL 명령문
• 뷰, 시퀀스, 동의어 등과 같은 데이터베이스 객체의 이름 변경 가능
• 사용법

• 사용 예
– addr_second 테이블 이름을 client_address로 변경하여라.
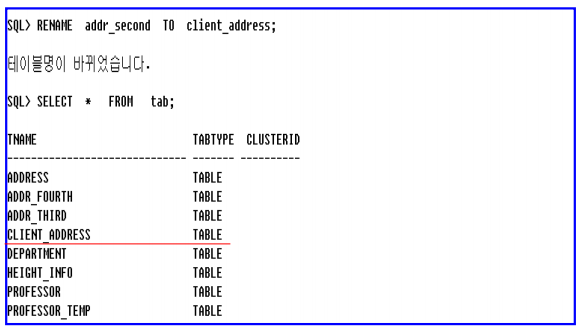
테이블 삭제
• 기능
– 기존 테이블과 데이터를 모두 삭제
– DROP TABLE 명령문 사용
– 삭제된 테이블 칼럼에 대해 생성된 인덱스도 함께 삭제
– 삭제된 테이블과 관련된 뷰와 동의어 "invalid" 상태
– 삭제한 테이블의 기본 키나 고유 키를 다른 테이블에서 참조하고 있는 경우 삭제 불가능
• 참조하는 테이블(자식 테이블)을 먼저 삭제
• DROP TABLE 명령문 마지막에 CASCADE CONSTRAINTS 옵션을 사용하여 무결성 제약조건을 동시에
삭제
• 사용법

– cascade constraints : 삭제 대상 테이블의 기본 키나 고유 키를 참조하는 무결성 제약조건을 동시에
삭제하기 위한 옵션
• 사용 예
– addr_third 테이블을 삭제하여라.

TRUNCATE 명령문
• 기능
– 테이블 구조는 그대로 유지하고, 테이블의 데이터와 할당된 공간만 삭제
– 테이블에 생성된 제약조건과 연관된 인덱스, 뷰, 동의어는 유지
• DELETE 명령문과 차이
– DELETE 명령문
• 기존 데이터만 삭제하는 명령이며, ROLLBACK 가능
• WHERE 절을 이용하여 특정 행만 삭제 가능
– TRUNCATE 명령문
• 기존 데이터 삭제뿐 아니라, 물리적인 저장 공간까지 반환
• DDL 문이므로 ROLLBACK 이 불가능
• WHERE 절을 이용하여 특정 행만 삭제하는 것이 불가능
• 사용법

• 사용 예
– client_address 테이블의 데이터와 할당된 공간을 삭제하여라.

DELETE, DROP, TRUNCATE의 비교
1. DELETE 명령어 사용
DELETE 명령어를 사용하여 TABLE의 행을 삭제할 수 있다.
예를 들어 EMP TABLE에서 모든 행을 삭제하는 명령문은 다음과 같다.
SQL > DELETE FROM emp;
◈ DELETE 문을 사용할 때 TABLE이나 CLUSTER에 행이 많으면 행이 삭제될 때마다 많은 SYSTEM
자원이 소모된다. 예를 들어 CPU 시간, REDO LOG 영역, TABLE이나 INDEX에 대한 ROLLBACK
SEGMENT 영역 등의 자원이 필요하다.
◈ TRIGGER가 걸려있다면 각 행이 삭제될 때 실행된다.
◈ 이전에 할당되었던 영역은 삭제되어 빈 TABLE이나 CLUSTER에 그대로 남아 있게 된다.
2. DROP과 CREATE 명령어 사용
TABLE을 삭제한 다음 재생성할 수 있다.
예를 들어 EMP TABLE을 삭제하고 재생성하는 명령문은 다음과 같다.
SQL > DROP TABLE emp;
SQL> CREATE TABLE emp (......);
◈ TABLE이나 CLUSTER를 삭제하고 재생성하면 모든 관련된 INDEX, CONSTRAINT, TRIGGER도
삭제되며, 삭제된 TABLE이나 CLUSTERED TABLE에 종속된 OBJECTS는 무효화된다.
◈ 삭제된 TABLE이나 CLUSTERED TABLE에 부여된 권한도 삭제된다.
3. TRUNCATE 명령어 사용
SQL명령어 TRUNCATE를 사용하여 TABLE의 모든 행을 삭제할 수 있다.
예를 들어 EMP TABLE을 잘라내는 명령문은 다음과 같다.
SQL> TRUNCATE TABLE emp:
◈ TRUNCATE 명령어는 TABLE이나 CLUSTER에서 모든 행을 삭제하는 빠르고 효율적인 방법이다.
◈ TRUNCATE 명령어는 어떤 ROLLBACK 정보도 만들지 않고 즉시 COMMIT 한다.
◈ TRUNCATE 명령어는 DDL 명령문으로 ROLLBACK 될 수 없다.
◈ TRUNCATE 명령문은 잘라 버릴 TABLE과 관련된 구조(CONSTRAINT, TRIGGER 등)와 권한에
영향을 주지 않는다.
◈ TRUNCATE 명령문이 TABLE에서 ROW를 삭제하면 해당 TABLE에 걸려 있는 TRIGGER는 실행되지
않는다.
◈ AUDIT 기능이 ENABLE 되어 있으면, TRUNCATE 명령문은 DELETE 문에 해당하는 AUDIT 정보를
생성하지 않는다. 대신 발생한 TRUNCATE 명령문에 대한 단일 AUDIT RECORD를 생성한다.
DELETE/ TRUNCATE/ DROP의 비교
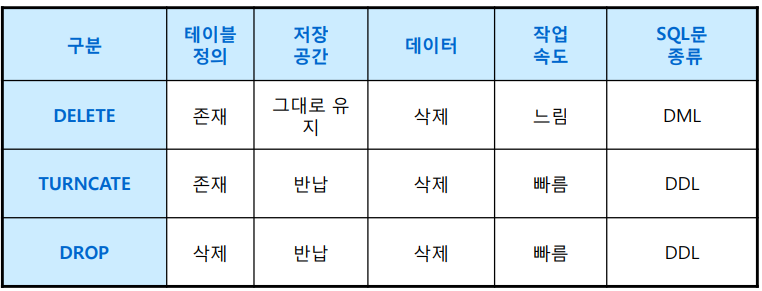
테이블 정의는 DROP 명령어를 사용한 테이블 삭제일 경우만 가능하며, 나머지의 경우는 테이블의 정의가
남는다. DELETE를 제외하고 TRUNCATE, DROP은 사용공간(저장공간)을 반납하여 다른 곳에서 해당공간을 재사용 가능하다.( Drop … Purge 경우 ) 작업속도는 DELETE를 이용한 데이터 삭제의 경우 삭제되는 행마다 로그를 기록하기 때문에 속도가 저하된다.
주석 추가
• 기능
– 테이블이나 칼럼에 최대 2,000 바이트까지 주석을 추가
– COMMENT ON TABLE … IS 명령문 이용
– 추가된 주석 확인
• ALL_COL_COMMENTS, USER_COL_COMMENTS, ALL_TAB_COMMENTS 데이터 사전 질의
• 사용법 : 테이블에 주석 추가

• 사용법 : 칼럼에 주석 추가

• 사용 예
– 주소록 테이블에서 "고객 주소록 관리하기 위한 테이블"이라는 주석을 추가하여라.

• 사용 예
– 주소록 테이블의 name 칼럼에 "고객이름‟이라는 주석을 추가하여라.

3. 데이터 사전
• 개요
– 사용자와 데이터베이스 자원을 효율적으로 관리하기 위한 다양한 정보를 저장하는 시스템 테이블의 집합
– 사전 내용의 수정은 오라클 서버만 가능
• 오라클 서버는 데이터베이스의 구조, 감사, 사용자 권한, 데이터 등의 변경 사항을 반영하기 위해 지속적
수정 및 관리
– 데이터베이스 관리자나 일반 사용자는 읽기 적용 뷰에 의해 데이터 사전의 내용을 조회만 가능
– 실무에서는 테이블, 칼럼, 뷰 등과 같은 정보를 조회하기 위해 사용
• 데이터 사전의 관리 정보
– 데이터베이스의 물리적 구조와 객체의 논리적 구조
– 오라클 사용자 이름과 스키마 객체 이름
– 사용자에게 부여된 접근 권한과 롤
– 무결성 제약조건에 대한 정보
– 칼럼별로 지정된 기본값
– 스키마 객체에 할당된 공간의 크기와 사용 중인 공간의 크기 정보
– 객체 접근 및 갱신에 대한 감사 정보
– 데이터베이스 이름, 버전, 생성날짜, 시작모드, 인스턴스 이름 정보
데이터 사전의 종류
• 개요
– 다수의 사용자가 동일한 데이터를 공유
– 읽기 전용 뷰로 구성
– 데이터베이스 관리자나 사용자에게 데이터 사전에 저장된 정보 조회 허용
– 용도에 따라 USER, ALL, DBA 접두어를 사용하여 분류
[표 11.1] 접두어 종류에 따른 데이터 사전 뷰

USER_ 데이터 사전 뷰
• 기능
– 일반 사용자와 가장 밀접하게 관련된 뷰
– 자신이 생성한 테이블, 인덱스, 뷰, 동의어 등의 객체나 해당 사용자에게 부여된 권한 정보 조회
• 사용 예
– USER_ 데이터 사전 뷰 조회 예
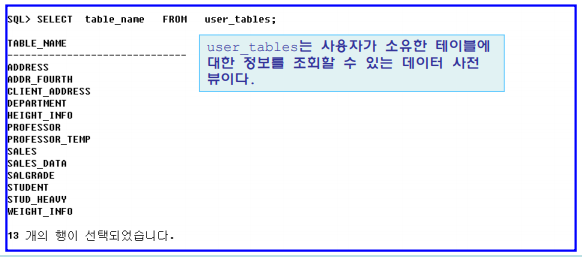
ALL_ 데이터 사전 뷰
• 기능
– 데이터베이스 전체 사용자와 관련된 뷰
– 해당 객체의 소유자를 확인가능
• OWNER 칼럼 존재
– 사용자는 ALL_ 사전 뷰를 이용하여 접근할 수 있는 모든 객체에 대한 정보 조회 가능
• 사용 예
– ALL_ 데이터 사전 뷰 조회 예
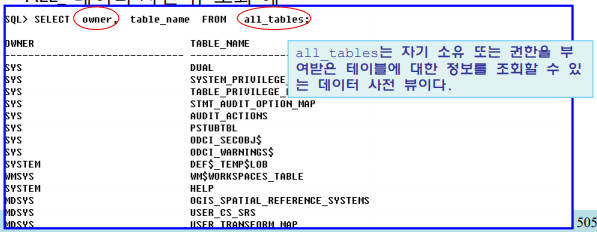
• DBA_ 데이터 사전 뷰
– 시스템 관리와 관련된 뷰
– DBA 나 SELECT ANY TABLE 시스템 권한을 가진 사용자
– 사용자 접근 권한, 데이터베이스 자원관리 목적
• 사용 예
– DBA_ 데이터 사전 뷰 조회 예
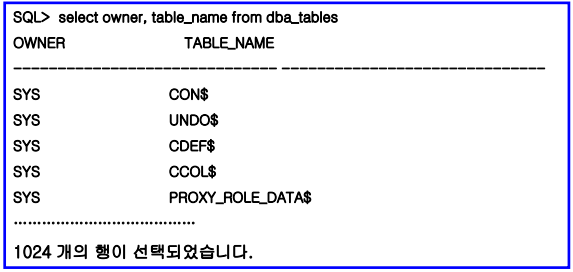
데이터 사전의 종류
[표 11.2] 데이터베이스 관리를 위해 자주 사용하는 데이터 사전 뷰
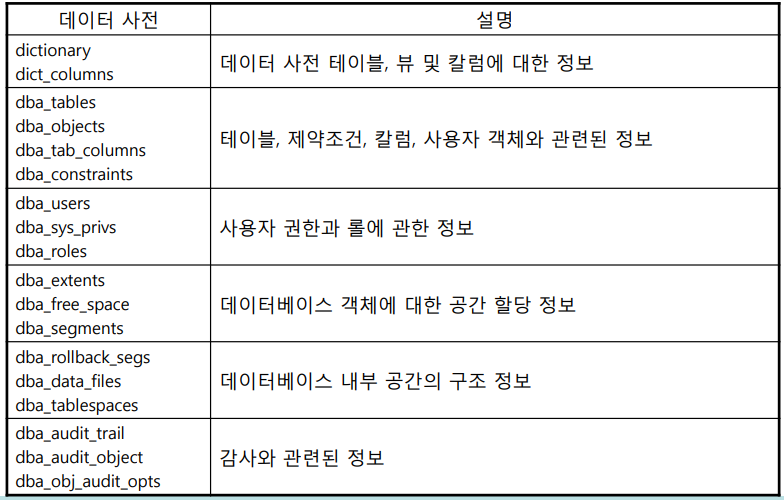
사용자 테이블 정보 조회
• USER_TABLES
– 테이블이 저장된 테이블스페이스 이름, 데이터가 저장된 물리적 공간 그리고 블록 파라미터 정보 등과
같은 정보를 저장
• 사용 예
– 테이블 이름이 ADDR로 시작하는 테이블의 이름, 테이블이 저장된 테이블스페이스 이름, 최소
확장영역 수와 최대 확장영역 수를 출력하여라.
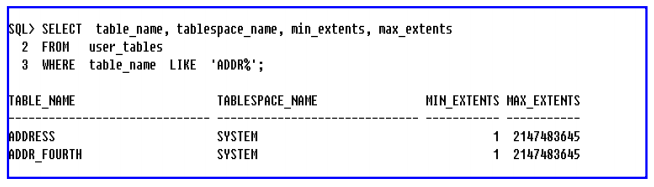
USER_OBJECT
• 기능
– 사용자가 생성한 테이블 정보와 함께 인덱스, 시퀀스, 동의어, 뷰 같은 객체에 대한 이름, 종류, 생성
날짜 등 정보 저장
• 사용 예
– 객체의 종류가 테이블이고 이름이 ADDR로 시작하는 객체의 이름, 종류, 생성날짜를 출력하여라.
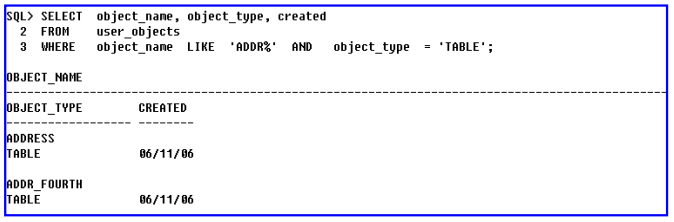
USER_CATALOG
• 기능
– 사용자 소유로 생성된 모든 객체 이름과 객체 종류에 대한 정보 저장
– Table_name : 객체 이름
– Table_type : 객체 종류
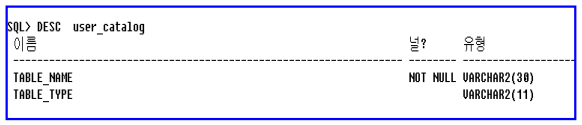
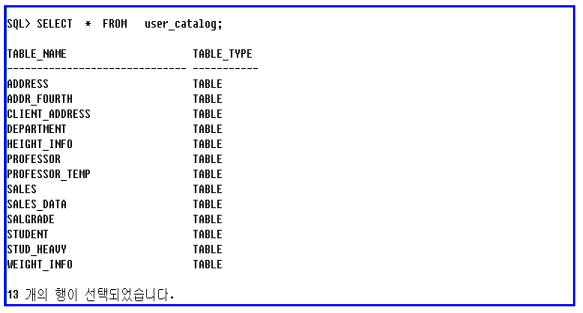
• 사용 예
'DataBase > 데이터베이스' 카테고리의 다른 글
| [풀스택과정] 데이터베이스 12. 인덱스 관리 (0) | 2023.02.09 |
|---|---|
| [풀스택과정] 데이터베이스 11. 데이터 무결성 (0) | 2023.02.09 |
| [풀스택과정] 데이터베이스 9. 데이터 조작어 (0) | 2023.02.07 |
| [풀스택과정] 데이터베이스 8. 서브쿼리 (0) | 2023.02.07 |
| [풀스택과정] 데이터베이스 7. 조인 (0) | 2023.02.06 |