
1. 데이터 변경 및 요약
1. 데이터 마트
- 데이터웨어하우스와 사용자 사이의 중간층에 위치
- 데이터의 한 부분으로서 특정 사용자가 관심을 갖는 하나의 부서 중심의 데이터웨어하우스라고 할 수 있다.
- reshape 패키지, sqldf 패키지, plyr 패키지, data.table 패키지 활용하여 데이터 마트 구성할 수 있다.
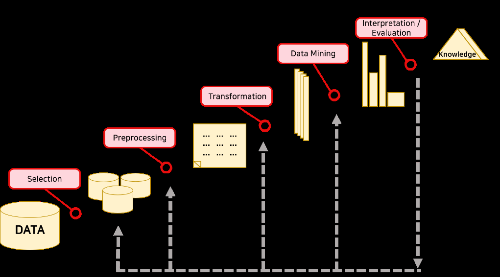
참고) KDD 분석방법론
참고) R에서 패키지 사용법
1) install.packages(“패키지명”)
– 패키지 다운로드 및 로컬 장소에 압축 풀기
2) library(패키지명)
– 메모리(주기억장치)로 패키지 로딩하기
2. reshape 패키지
- 2개의 핵심적인 함수로 구성 : melt(), cast()
| melt() | 녹이는 함수 쉬운 casting을 위해 데이터를 적당한 형태로 만들어주는 함수 Wide Format to Long Format |
| cast() | 모양을 만드는 함수 데이터를 원하는 형태로 계산 또는 변형시켜주는 함수 Long Format to Wide Format |
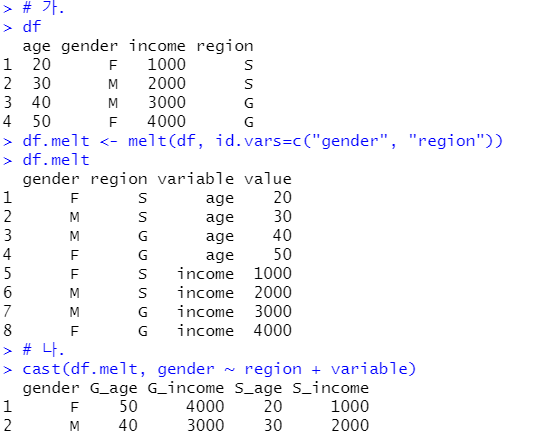
[기출문제] 아래 ‘가’의 R 코드를 수행한 후 ‘나’와 같이 재구성된 데이터를 얻기 위해 사용해야 하는 cast 함수는?
<아래>
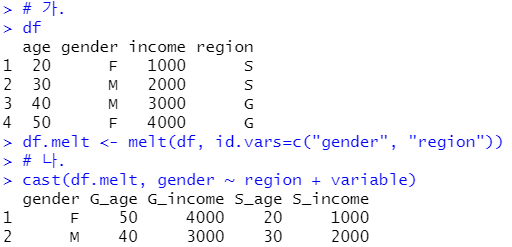
정답: cast(df.melt, gender ~ region + variable)
(풀이)
3. sqldf 패키지
– R에서 SQL 명령을 사용하게 해주는 패키지 (예) sqldf(“select * from iris”)
- (예제) sqldf() 함수를 이용하여 iris 데이터셋의 전체 행의 수 알아내기
4. plyr 패키지
- apply 함수를 기반으로 데이터와 출력변수를 동시에 배열로 치환하여 처리하는 패키지
- split – apply – combine(분리-처리-결합) 방식으로 데이터를 분리하고 처리한 다음, 다시 결합하는 가장 필수적인 데이터 처리 기능 제공
| 입력되는 데이터 형태 | ||||
| 출력되는 데이터 형태 | 데이터프레임(dataframe) | 리스트 (list) | 배열 (array) | |
| 데이터프레임 | ddply | ldply | adply | |
| 리스트 | dlply | llply | alply | |
| 배열 | daply | laply | aaply | |
5. data.table 패키지
- R에서 가장 많이 사용하는 데이터 핸들링 패키지 중 하나로 대용량 데이터의 탐색, 연산, 병합에 유용
- 기존 data.frame 방식보다 월등히 빠른 속도 - 특정 컬럼을 key 값으로 색인을 지정한 후 데이터를 처리
- 빠른 grouping과 ordering, 짧은 문장 지원 측면에서 데이터프레임보다 유용함
[기출문제] 아래의 R 코드를 실행했을 때 출력되는 결과는 무엇인가?
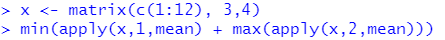
(풀이)

2. 기초 분석 및 데이터 관리
1. 결측값과 결측값 처리
1) 결측값 : NA
- 결측값(Missing data) 처리를 위해 많은 시간을 쓰는 것은 비효율적
- R에서는 결측값을 NA(not available)로 처리
cf) 불가능한 값은 NaN(not a number)로 처리 (예) √−25
- 결측값을 입력하는 방법 → 결측값을 입력할 자리에 NA로 표기
- 결측값 처리 함수(2가지)
1) is.na() → 결측값 인지 여부 확인하는 함수, 결측값이면 TRUE, 결측값이 아니면 FALSE
2) na.omit() → 결측값을 가진 행 제거하는 함수
[기출문제] 아래의 자료는 airquality 데이터프레임의 일부이다. 본 데이터는 다수의 결측치(NA)를 포함하고
있다. 다음 중 결측치가 포함된 관측치를 제거한 데이터프레임을 얻기 위한 명령어로 가장 적절한 것은?
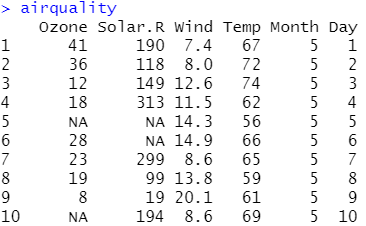
정답: na.omit(airquality) (풀이)
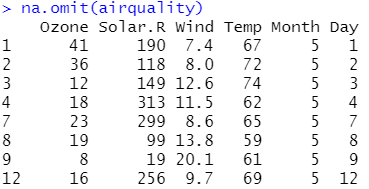
2) 결측값 처리 방식
(1) 단순 대치법(single imputation)
① completes analysis : 결측값의 갖는 레코드를 삭제
② 평균 대치법
- 관측 및 실험을 통해 얻어진 데이터의 평균으로 대치
- 비조건부 평균 대치법 : 관측 데이터의 평균으로 대치
- 조건부 평균 대치법 : 회귀분석을 통해 데이터를 대치
③ 단순확률 대치법
- 평균대치법에서 추정량 표준 오차의 과소 추정문제를 보완한 방법으로 Hot-deck 방법, nearest Neighbor 방법이 있음
(2) 다중 대치법(multiple imputation)
- 단순 대치법을 m번 실시하여, m개의 가상적 자료를 만들어 대치하는 방법
3) R의 결측값 처리 관련 함수
| complete.cases() | 데이터내 레코드에 결측값이 있으면 FALSE, 없으면 TRUE를 반환 |
| is.na() | 결측값이 NA인지의 여부를 TRUE/FALSE로 반환 |
| na.omit() | 결측치를 포함한 행 제거 |
| Amelia 패키지 Amelia() | time-series-cross-sectional data set (여러 국가에서 매년 측정된 자료)에서 활용 |
2. 이상값(Outlier)과 이상값 처리
(1) 이상값(Outlier)
- 의도하지 않은 현상으로 입력된 값 또는 의도한 극단값
- 잘못 입력된 값 또는 의도하지 않은 현상으로 입력된 값이지만 분석 목적에 부합되지 않는 값
- 부정사용방지시스템(Fraud Detection System, FDS)에서 규칙을 발견하는데 사용할 수 있다.
(2) 이상값의 인식(5가지)
① ESD(Extreme Studentized Deviation) 알고리즘
-- ESD : 평균으로부터 k*표준편차만큼 떨어져 있는 값들을 이상값으로 판단, 일반적으로 k=3
② 기하평균-2.5*표준편차 < data < 기하평균+2.5*표준편차
③ Q1 – 1.5*IQR < data < Q3 + 1.5*IQR cf) IQR(Inter Quantile Range) = Q3 – Q1
④ 이상값을 상자그림(boxplot)으로도 식별할 수 있다
⑤ outliers 패키지를 사용
(3) 이상값의 처리
① 절단(trimming)
- 이상값이 포함된 레코드를 삭제
② 조정(winsorizing)
- 이상값을 상한 또는 하한값으로 조정
[기출문제] 여섯 가지 종류의 닭 사료 첨가물의 효과를 비교하기 위한 데이터와 그래프이다. 아래의 대한
설명으로 다음 중 적절하지 않은 것은 무엇인가?
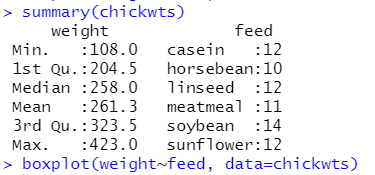
① weight의 중앙값은 horsebean 그룹이 가장 작다.
② 이상값은 존재하지 않는다.
③ meatmeal 그룹과 linseed 그룹의 weight의 평균이 유의한 차이가 있는지 알 수 없다.
④ horsebean 그룹에서 weight가 150보다 작은 개체가 약 50%가량 된다.
정답: ②
'Study > ADsP' 카테고리의 다른 글
| [ADsP 정리] 3. 데이터 분석(4) (1) | 2024.05.20 |
|---|---|
| [ADsP 정리] 3. 데이터 분석(3) (1) | 2024.05.17 |
| [ADsP 정리] 3. 데이터 분석(1) (0) | 2024.05.13 |
| [ADsP 정리] 2. 데이터 분석기획(2) (1) | 2024.05.09 |
| [ADsP 정리] 2. 데이터분석 기획 (0) | 2024.05.06 |